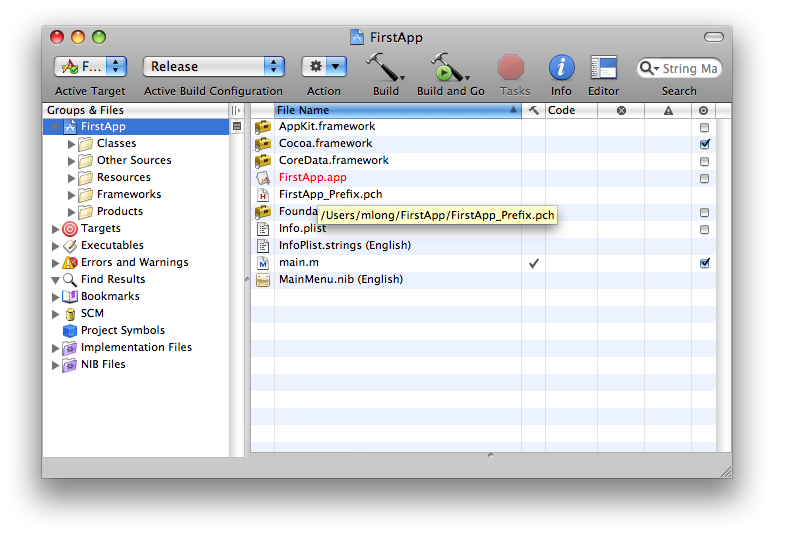
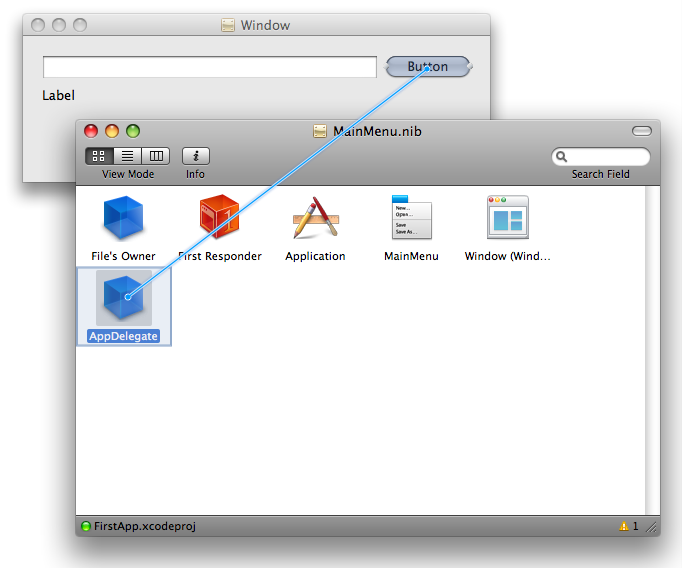
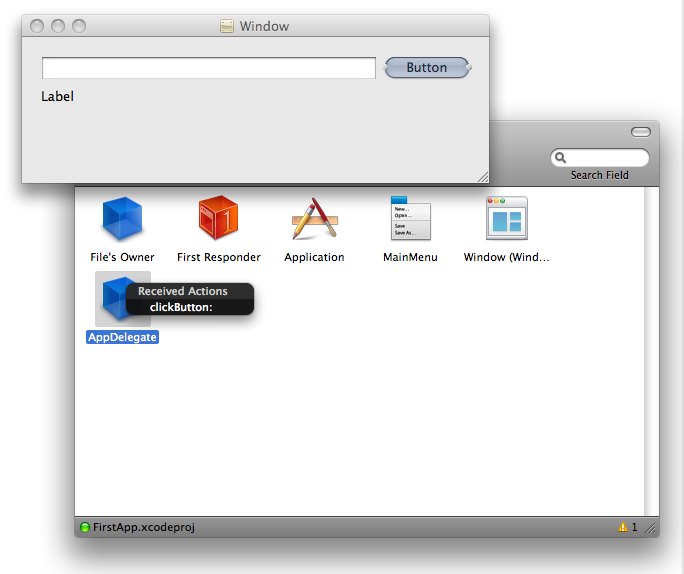
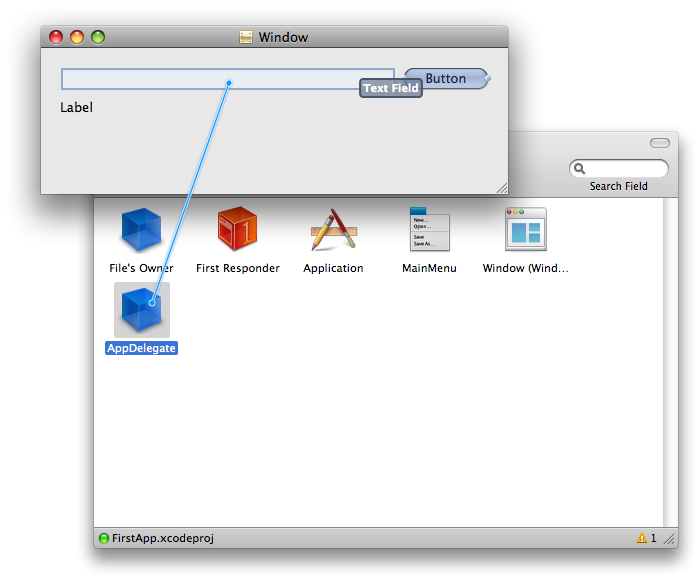
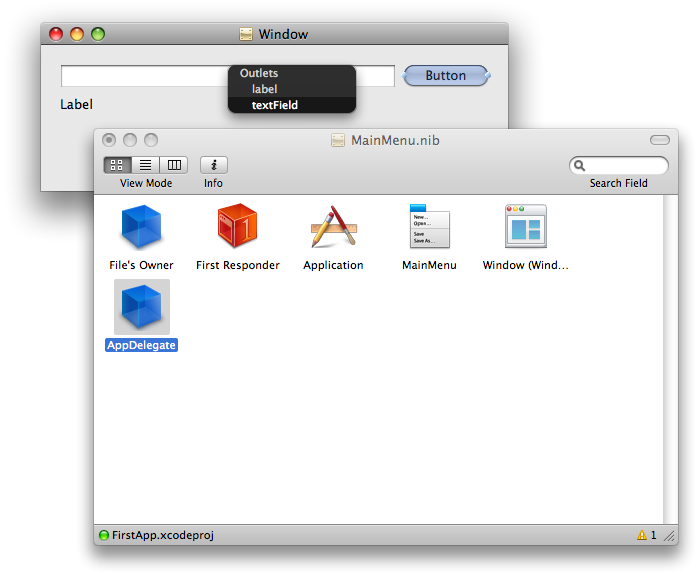
The statelessness of the web continues to challenge every web devloper no matter if you’re a newbie or a seasoned professional. Wherever I am in the development experience landscape, I am no exception.
While working with an ASP .NET 2.0 TreeView for the first time I was hopeful that there might be some built in capabilities that would make my experience similar to what you might expect in the WinForms TreeView.
When working with the TreeView in WinForms, I simply create a derived TreeNode object for every type of entity I expected to represent in the TreeView. That way, when I get a SelectedNodeChanged event, I can simply see what the node type is and respond accordingly. So I set up the event handler in my ASP .NET TreeView and went to look at the signature and realized that the only thing I was given was the sender (the TreeView itself) and a generic EventArgs object. This is different than what you get in the WinForms TreeView. It actually provides the the selected node object in the event args. Well, I reasoned, just because I’m not given the node object doesn’t mean that I can’t just grab it out of the TreeView’s SelectedNode property.
Now, keep in mind that I had created a base TreeNode type that all of my TreeNodes could inherit from, but to be safe I just typecasted to the TreeNode type when I accessed the selected node in the TreeView.
Here is what I did:
[csharp]TreeNode selectedNode = ((TreeView)sender).SelectedNode;[/csharp]
I then used the GetType() method to determine whether I was getting back the type I was expecting. And herein lies the problem. As I moused over selectedNode while debugging, the type it was showing was TreeNode. No matter which of my inherited node types I had added to the TreeView on page load, the SelectedNode parameter always returned a TreeNode type.
At this point, I realized that the statelessness of the web had gotten me again. I should have realized that this would be the case. The TreeView only knows how to make generic TreeNodes and since the TreeView has to be built on each successive trip to the server, it doesn’t know how to make my extended tree nodes.
In thinking through a bit more, and with a bit of help from some guys on the CodeProject.com message boards, I realized that the only way to do what I was wanting was to create my own derived TreeView and create a way to store the types that I needed in the ViewState. Oy! It was starting to seem that this way of handling a TreeNode getting clicked was getting much more complicated than it needed to be.
I decided to head back to the drawing board or, actually, the MSDN documentation and see what all the TreeView had to offer me. What it all boils down to are three different properties I can access. They are:
TreeNode.Text: This is the text that gets displayed for the particular node when rendered.
TreeNode.Value: This is the value of the node which has to be unique at any given hierarchy depth.
TreeNode.ValuePath: This is the full value path to the current node.
Thes properties make it pretty clear that the way to handle TreeNodes in ASP .NET 2.0 is to use the ValuePath to determine where the selected node lies in the hierarchy. The Text property is only useful in that it will display something to the user. The Value property is useful in that it will allow you to store an identifier for the current node. It’s the ValuePath property, however, that allows you to parse out everything you need to respond accordingly.
Now that I knew that I needed to determine a good way to parse the ValuePath, I stubmled upon a new problem. In the event handler for the node change, I was simply building a URL to redirect to and then calling Response.Redirect(). The problem is that if you want to simply redirect to the current page and display a View in the page (I was was using a MutiView, which is another powerful control available in ASP .NET 2.0) based on parameters you’ve passed in the URL, you’re going to have problems with the TreeView not retaining its display. The TreeView is expecting that you will simply post back to the server and it will be able to retain it’s layout in the ViewState. In my case, though, when I clicked the TreeNode, it was doing a Response.Redirect which, when the new page loads, will cause it to not be a PostBack which simply means that the TreeView will re-render in it’s default state (which is determined by the ExpandDepth property that is set in the designer or code views).
What this means is that each time I would click a node in the TreeView, when the page loaded again, my TreeView would be collapsed again to its default expansion depth which I had set to 1. So, how could I ensure that when the page loads, my TreeView is expanded properly?
I decided to take the ValuePath of the selected node and append it to the URL as a parameter as well and then use that on the other side to expand the TreeView to the same state as it was before the node was clicked. Of course, first you have to UrlEncode the ValuePath like this:
string encodedValuePath = HttpUtility.UrlEncode(valuePath);
And then you can add it to the URL you are redirecting to, but here is how I handle expanding the nodes properly when the page is loaded again:
[csharp]if (Request.Params[“ValPath”] != null)
{
// Decode the ValPath parameter
string valPath = HttpUtility.UrlDecode(Request.Params[“ValPath”]);
// Find the node we want to select according to the ValuePath
TreeNode node = tvMain.FindNode(valPath);
if (node != null)
{
// If we were able to find the node, we expand it and set its
// selected property.
node.Expand();
node.Select();
// Now we simply walk up the TreeNode hierarchy, expanding each
// parent node above us to ensure that the TreeView will display
// properly.
TreeNode tmpNode = node;
while (tmpNode.Parent != null)
{
tmpNode.Expand();
tmpNode = tmpNode.Parent;
}
}
}[/csharp]
I had orignally thought that simply selecting and expanding the selected TreeNode would be enough, but it didn’t actually work correctly until I did things this way.
You may be wondering at this point why I don’t simply use the NavigateUrl property on each node when I initially populate the TreeView. The issue is that the ValuePath property gets set at a later time and is not available when you first instantiate a TreeNode. If I tried to append the ValuePath to the NavigateUrl property at the time when the TreeNode was created, it would have thrown a null reference exception. On the other hand, when you just redirect in the node changed event handler as I was doing, you can grab the ValuePath of the currently selected node without problem.
Ok, so now that was working correctly. There was only one more thing I needed to do. I had to have a good way to parse the ValuePath property when the node changed event was fired. For this, I implemented the Strategy Pattern and created a Strategy Factory and ValuePathStrategy objects for each of the TreeNode entities. Basically, my Strategy Factory (which is a Singleton) takes the ValuePath as a parameter and determines from the first or second level in the ValuePath which type of strategy object to create and passes that object back to the caller. The caller can then simply access the Url property on the ValuePathStrategy object and redirect accordingly. Here is what the code basically looks like:
[csharp]protected void tvMain_SelectedNodeChanged(object sender, EventArgs e)
{
TreeView view = (TreeView)sender;
TreeNode node = view.SelectedNode;
if (node != null)
{
ValuePathStrategyBase vbase = ValuePathStrategyFactory.
Instance.GetStratey(node.ValuePath, view.PathSeparator);
if (vbase != null)
{
Response.Redirect( “~/Default.aspx?” + vbase.Url, true);
}
}
}[/csharp]
Notice I’ve also passed in the PathSeparator so each level of the path can be easily tokenized with the String.Split method. Each of what would have originally been extended tree nodes are now strategy objects that provide different URL parameters based on what will be needed when the page loads including the view, which specifies which view in my MultiView to display, the name of the parameter that view needs in order to load its data, and the parameter value itself which, in the case of my application, gets passed to an ObjectDataSource which has a table adapter for the corresponding data in the database.
I’m not sure that my methods for handling my TreeView are the best, however, I’m pretty happy with the outcome. I’ve been able to keep everything relatively clean code wise and the way I’ve done things seems to uphold the rules of designing an application for the web as opposed to WinForms.